Introducing PureCPP: A New Open Source RAG Framework Built for Speed and Scale

- AI Infrastructure, Developer Tools, Open Source
Introducing PureCPP a high-performance RAG framework built to solve real-world challenges in AI retrieval.
Developed by PureAI, PureCPP is an open-source framework designed to optimize every stage of the RAG pipeline, from data ingestion and chunking to embedding, retrieval, and metadata management.
Why? Because while Retrieval-Augmented Generation (RAG) significantly improves the accuracy of Large Language Models (LLMs) by integrating external data at inference time, it often introduces complex trade-offs in cost, latency, and scalability.
PureCPP was built to overcome these challenges delivering faster, more efficient, and highly customizable RAG workflows ready for production at scale.
What Is RAG and Why Does It Matter?
Retrieval-Augmented Generation allows LLMs to “look up” information dynamically from external knowledge sources instead of relying solely on their training data. This means responses are more accurate, contextually aware, and up-to-date.
However, traditional RAG setups can quickly become resource-intensive:
-
Indexing can be slow and expensive.
-
Retrieval often adds latency.
-
Inference can strain both CPU and GPU resources.
That’s where PureCPP stands out.
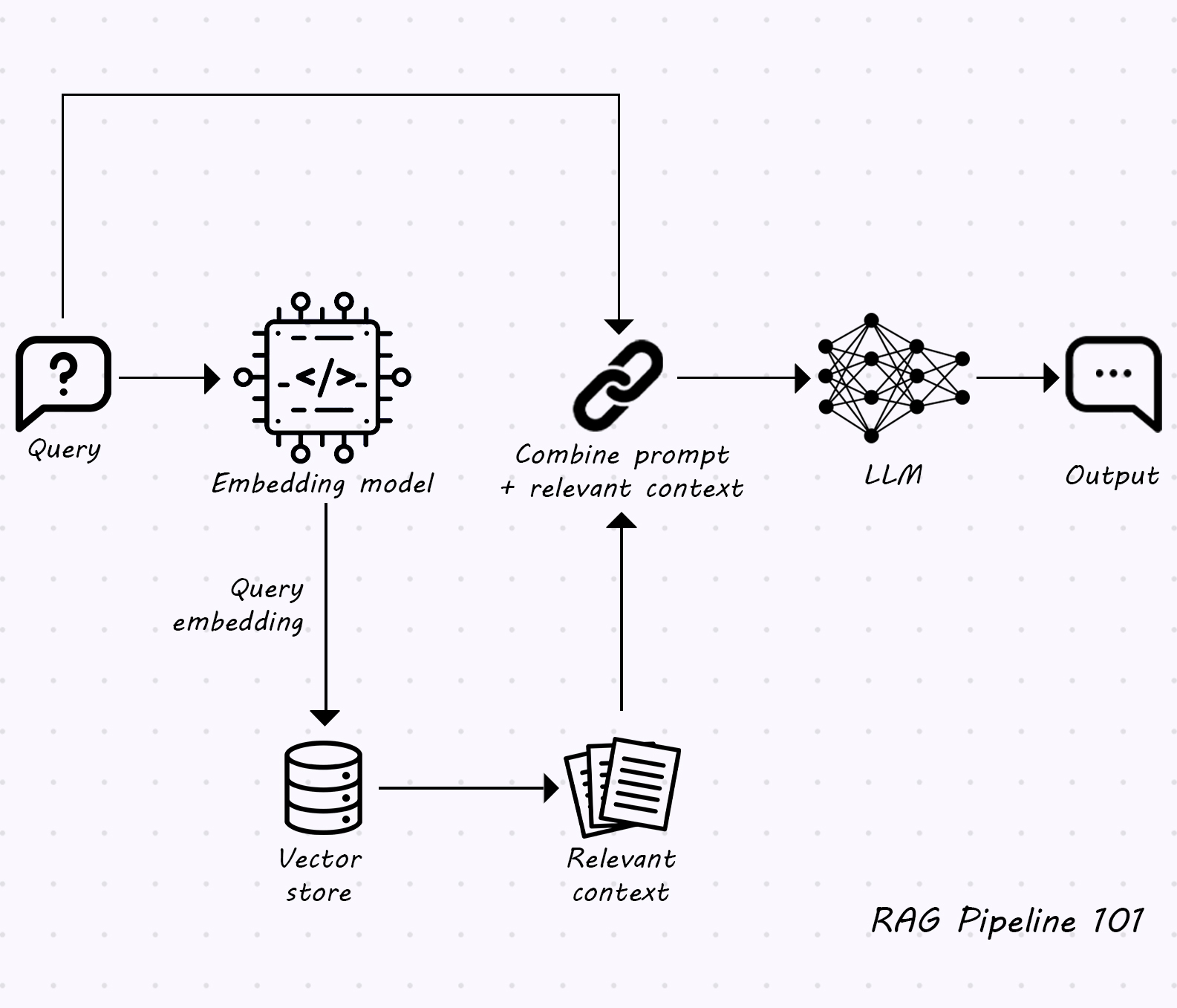
Meet PureCPP: Built for Performance
PureCPP is a modular, blazing-fast RAG framework written in C++, with Python bindings to ensure developer accessibility. It’s engineered for real-time applications, high-throughput systems, and teams that need granular control over their AI stack.
Why C++?
Most RAG frameworks today are written in Python. We chose C++ for our core because:
-
Performance: C++ offers lower-level memory management and closer proximity to hardware, making it ideal for processing massive datasets with minimal latency.
-
Parallelism: With robust support for multithreading, we can fully leverage multi-core CPUs and GPUs, optimizing for concurrent tasks like chunking and embedding.
-
Compatibility: Python bindings allow easy integration into modern ML workflows, giving developers the speed of C++ with the ease of Python.
-
Scalability: C++ enables a future-proof architecture capable of supporting increasingly large models and vector databases.
By combining C++ efficiency with Python usability, PureCPP offers the best of both worlds.
PureCPP in Numbers: Performance Benchmarks
Comparison of CPU usage in identical processes
Up to 30% CPU usage savings
Estimated time for splitting text into chunks of 700 characters
66% speed increase
Estimated time for PDF extraction
60% speed increase
Comparison of CPU usage in identical processes
Up to 30% CPU usage savings
Estimated time for splitting text into chunks of 700 characters
66% speed increase
Estimated time for PDF extraction
60% speed increase
How PureCPP Works
At its core, PureCPP is built to be lean, efficient, and extensible. Here’s what makes it powerful:
Clean and Customizable Data Loaders
Support for structured and unstructured sources, including PDFs, TXT, and JSON, with preprocessing pipelines.
Smart Chunking with Regex and Embeddings
Optimized chunking and deduplication with language-aware boundaries and regex cleaning logic.
Embedding That Just Works
PureCPP integrates seamlessly with popular embedding models and is built for parallel generation.
Metadata-Aware Retrieval
Metadata is first-class: everything from creation date to document category is indexed and available during retrieval.
Try It Now on GitHub
and be one of the first to implement it in your work and projects!